
A succinct guide to machine learning for product managers

This product-centric overview of machine learning is written by Neal Lathia, Senior Data Scientist at Skyscanner.
![]()
It’s now becoming common for me to hear that product owners, technical managers and designers are turning to popular online courses to learn about machine learning (ML). I always encourage it — in fact, I did one of those courses myself (and blogged about it).
However, it’s not always clear how much benefit someone whose goal is to design, support, manage, or plan for products that use machine learning will get from doing an online course in ML.
These courses throw you into the deep end, asking you to start programming classifiers, when many non-technical team mates are only looking for sufficient knowledge to be able to work in teams that are creating an ML-driven product. It’s a bit like wanting to drive a car, and therefore signing up to a course on combustion engines — probably a little bit too detailed for practical day-to-day driving!
I therefore recently ran a session at Skyscanner that aimed to cover machine learning from a non-technical, product-centric perspective. We first covered definitions, and then moved on to a number of key issues that are important to keep in mind to create successful products that go beyond ‘just’ the ML. Here, I go into what I taught in that session.

Part 1: Machine learning, without the math
We began by addressing the burning question on everybody’s mind: what is machine learning? I quoted the first sentence of this paper by Pedro Domingos: “Machine learning systems automatically learn programs from data.”
That’s basically it. Machine learning is a way of creating a program that does something, without you having to figure out exactly how to do it. Compare that to the usual way we create programs, where we need to be able to code every step (if this happens, then do that, and then do that).
In practice, the way this happens is that you give an ML algorithm a data set with examples, and the algorithm’s job is to learn from the examples. Forget the math that is happening under the hood: it is enough to know that, at the heart of every ML algorithm, is the concept of error . ML algorithms are all trying to minimize how many mistakes they make.
There are many families of ML algorithms; the most common two are known as supervised and unsupervised learning. How can you recognize them in products? Let’s dive into some examples.
Unsupervised learning is about identifying patterns
The examples that are usually fed into unsupervised ML algorithms are characterized by the fact that there is no deterministic ‘correct’ answer that the algorithm needs to learn to predict. Products that use unsupervised learning are typically surfacing patterns in user data.
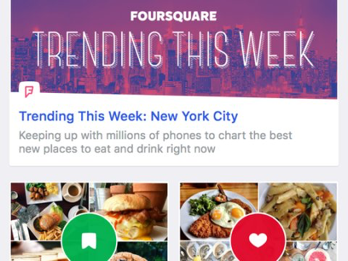
A simple example is “Trending this Week” on Foursquare. Is there any data out there that could tell us, objectively, that a venue should or should not trend this week? No. Instead, there is data that shows how Foursquare users were visiting venues that week — and patterns in that data create trending venues. Note that this is different from whether users think that the output of the algorithm is correct or not (“what? McDonald’s is trending?”).
Supervised learning is about predicting an outcome
The examples that are fed into supervised ML algorithms, instead, have a deterministic outcome that the algorithm needs to try and predict. The most classic example of this in action is spam-detection.
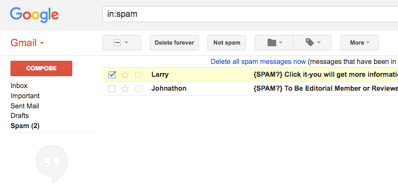
You give the algorithm examples of emails that are and are not spam; each example email is labeled with whether it is spam or not. Then, given a new email, you ask the algorithm: is this spam? Remember, the algorithm’s goal is to minimize how many mistakes it makes. If the algorithm says yes, you push that email into the user’s spam box.
Supervised & unsupervised learning often looks similar in products
While the examples above make the difference between supervised and unsupervised learning look quite straightforward, there are many cases where the difference is not so clear. Consider, for example,“Discover Weekly” and “Recommended Songs” (at the end of a playlist) by Spotify. Both are being pitched to users as a recommendation. However, they are (probably!) using different kinds of learning under the hood.

Discover weekly looks like a supervised learning problem: the ML is given examples of songs that you have listened to, starred, etc., and is tasked with finding a list of songs that you are likely to listen to. Songs that are recommended for a playlist looks like an unsupervised learning problem: the ML algorithm is looking for co-occurrence patterns in millions of playlists, to find songs that are commonly added to playlists that contain the songs that you have already added to yours.
There are technical terms for what products are trying to do
Data scientists will often use technical terms to describe the ML problem that they are working on. Are you building a product that is…?
- Helping users find the right thing when they search? This is a ranking problem. Google, Bing, and Twitter search are all doing this — trying to sort things when you query so that the thing you’re looking for is at the top.
- Giving users things they may be interested in, without them explicitly searching? This is a recommendation problem. Netflix, Spotify, who-to-follow on Twitter are examples — these products are suggesting things to engage users.
- Figuring out what kind of thing something is? This is a classification problem. Gmail spam/not spam and Facebook photos (detecting faces) are examples here.
- Predicting a numerical value of a thing? This is a regression problem. Predicting how much a flight will cost in two hours is an example.
- Putting similar things together? This is clustering in action. Amazon’s customers-als0-bought is the most notable example, and we saw Spotify’s playlist addition recommendations above as well.
- Finding uncommon things? This is usually anomaly detection. Most “trending” products (Foursquare, Twitter, Facebook) are examples, that surface things that are being tweeted/visited/talked about more than usual.
In general, 1–4 are examples of supervised learning, and 5 & 6 fall into the unsupervised learning domain.
However, there are obvious cross-overs here: for example, a recommendation problem is a kind of classification problem — the algorithm is trying to predict whether a user would (or would not) be interested in a thing. For practical purposes, let’s leave those cross-overs to one side for now.
Part 2: Using ML in products
Technical team members who are building an ML product will be discovering and analyzing data, building data pipelines, feature engineering, selecting and optimizing algorithms, avoiding overfitting, running offline evaluations, and putting ML into production for online tests. However, as a product manager, there are a number of additional things to keep in mind that go well beyond the technicalities of ML in order to create a successful product. This part focuses on seven of those considerations.
1. Does the ML fit the product goal?
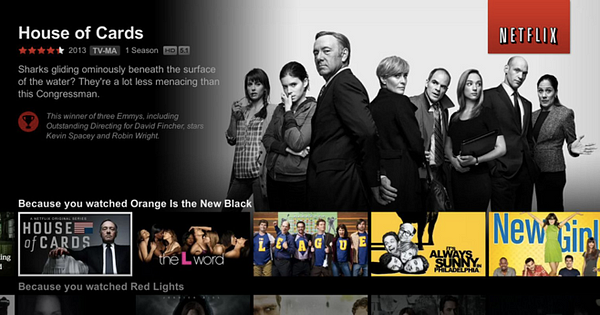
In 2006, Netflix launched a million dollar competition to improve their recommendation system. They asked researchers to develop a supervised learning algorithm that could predict how many stars a user would give a particular movie. The idea at the time was that being able to predict how many stars a user would give a film could be used to give better recommendations.
As I blogged about before, one of the major lessons from the competition, which is described in this paper and these slides, was that predicting a rating accurately was no longer as important as ranking films in the right way with other sources of data.
In other words, the problem that the ML was solving was different from the problem that Netflix wanted to solve in their product. For any new product that you are developing, you should ask: is the ML solving the problem that you want it to?
2. How does the product behave “around” the ML?
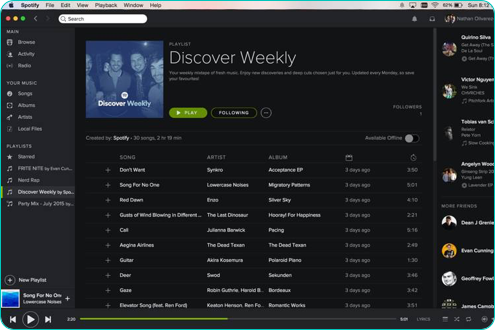
I’ll pick on Discover Weekly again. It’s a playlist that is generated by ML. However, somebody decided that it should be finite, that it should update on Mondays, and that your previous playlists should vanish when your new one comes along. All of these are examples of product decisions, which do not rely on ML.
It’s easy to imagine a version of Discover Weekly that would be an infinite playlist that updates on the fly and that stores all of the past songs somewhere for you to go back to.
In other words, while Discover Weekly is clearly a great product that uses ML, there are also a number of other decisions that were made which probably contributed just as much to its success: defining the product’s behavior around the ML itself is very important.
3. How should a product start using ML?
A common question regarding ML products is where to begin: it seems like a huge, near-insurmountable task requiring months of work. However, as Martin Zinkevich’s (highly recommended) document on best practices for ML engineering describes, you should not be afraid to ship a product that does not use machine learning. Many products can start to collect useful customer feedback using simple baselines; in the document, Martin quotes an example of sorting apps in an app store by download count (or popularity).
The key word here is simple. If you need to draw a state diagram that has tens of boxes to describe what your non-ML product is doing, then you’ve probably already started over-engineering an unnecessarily complex solution. One the other hand, if you can say (in one short sentence) what the product is doing (“we’re sorting by cheapest,” “we’re showing the most popular”) then you’re off to a good start.
4. What are you comparing with?
This next point follows on from the previous one that is about using a simple baseline. We typically think of early/MVP products in isolation: we build one thing in order to get it out there and see how customers react.
ML products are different because performance is always relative — even with your first iteration. For example, if your advanced ML algorithm is 95% accurate, but your simple baseline is 94% accurate, then you’re investing a huge amount of work for 1% gain. If, on the other hand, your ML algorithm is 75% accurate, but the simple baseline was 50%, then you’ve made a huge leap forward.
There are two important points here: first, performance is always relative to something. You need a baseline.
Second, to be able to compare things, you need well-defined metrics. In ML products, these are often split between offline (e.g., “how accurate is the algorithm at predicting historical data?”) and online (e.g., “how much more conversion do we get when we deploy the product with this algorithm?”) metrics.
5. How quickly should this product change?
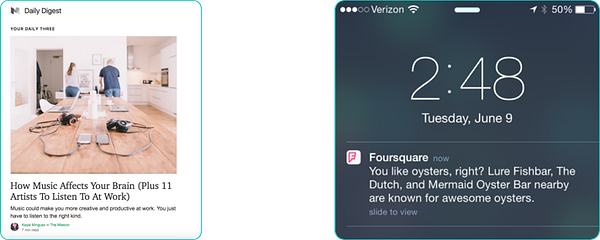
The speed with which the ML product’s output should change has a great impact on how you build it. For example, consider Medium’s ‘daily three’ email, or Quora’s digest email. There is probably some ML behind both of these — but the product is an email, which does not need to adapt, in real time, to any actions a user may take. Now, instead, consider Foursquare’s location-based notifications, or Google search. Every action that a user takes (going to a new neighborhood, adding in a new query) will result in a different output.
Understanding the ‘speed’ of the product not only allows you to tailor your system architecture to cater for this, but also impacts the experience that your users will have.
6. What interactions, actions, & control do users have?
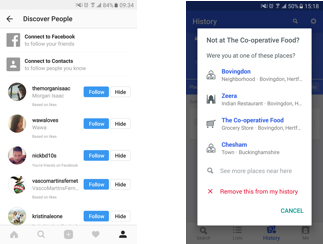
Data scientists will often be looking at what data is available, and look to build ML algorithms based on that. However, when creating a new product, teams will have the opportunity to define what data will be collected when designing user interactions: part of creating a new product is identifying what data can (and should) be collected to improve the product in the future. In fact, not logging data in early products is a source of frustration for many data scientists.
For example, Instagram’s friend recommendations allow users to follow or hide the suggested contacts, and Foursquare allows users to fix the places that it automatically detected users had visited. In doing so, both of these allow users to engage with the ML algorithm’s output, and provide new data — both positive (yes, follow!) and negative (no, hide!) examples. These can then be fed back to improve the algorithm.
The Instagram example also shows why users are recommended. Providing explanations for ML actions is an entire field of research, with one common theme: systems that explain how they work are often better received by users.
7. How could the product fail catastrophically?

In products that don’t use ML, ‘failure’ is often about bugs, crashes, or confusing interfaces. Since ML is intrinsically about training an algorithm via examples, the way products can fail takes on a whole variety of new dimensions (the image here is of Microsoft’s Tay Bot, which turned racist after being put online).
One of the most cited stories in this domain is about the US-based retail store Target. They had some kind of algorithm to compute the probability that a person was pregnant, and they used that to send coupons and discounts — a fairly typical use of ML. This system sent coupons for baby clothes to a teenage girl, causing her father to be outraged: why was his daughter targeted with coupons for baby clothes? Shortly later, though, Target received an apology from him: the girl was indeed pregnant.
So, what happened here? Well, the ML algorithm actually got its prediction right: it learned to accurately predict pregnancy from the examples it was given. The product, though, failed. There are many, many similar examples of ML products going wrong. All of them share a common theme: the way the products are used or applied was different to how the product designers envisaged. Whether this comes down to targeting customers based on sensitive inferences, to people goading a bot, to biased data sets being used to train face-detection algorithms, the product teams had not taken into account how the product would be used in context.
More reading on machine learning
Creating products that use ML is an increasingly multi-disciplinary activity. The session summarized above focused on defining ML (without the math), and highlighting seven issues that go beyond the ML when creating products — there are many more. If you’re looking to teach yourself more about machine learning for product managers, here is some recommended reading.
- Experience Design in the Machine Learning Era: The implications for designers and data scientists who create systems that learn from human behaviors.
- Top-N tips for talking with non-Data Scientists: Cross-disciplinary work is hard, until you’re speaking the same language.
- It’s ML, not magic: simple questions you should ask to help reduce AI hype: During the peak of the dot-com bubble, you’d be forgiven for thinking prefix investing was a legitimate tactic.
- The Logorrhean Theorem: A lot of over-hyped AI claims are being thrown around right now.
![]()
This product-centric overview of machine learning is written by Neal Lathia, Senior Data Scientist at Skyscanner.




