

What is autocapture for analytics?

Autocapture is an analytics feature for collecting commonly tracked user behavior data automatically, without the need for custom coding. This accelerates analytics setup time and reduces maintenance costs and the risk of data loss.
When you’re building a product, data is vital—particularly user behavior data that reveals what your users are clicking, what they’re ignoring, and where they’re encountering difficulties when interacting with your product.
Historically, obtaining this data required getting developers to add custom code to the product, and every type of user interaction needed its own unique snippet. But developers often have limited bandwidth, and spending time adding custom data tracking is not at the top of the priority list.
What if tracking events wasn’t such a complicated task? What if it required only a single line of code (that takes less than two minutes to implement)? Step up, autocapture.
What is autocapture for analytics?
Autocapture, sometimes referred to as autotrack, is an analytics method for collecting commonly tracked user behavior data, like clicks and form submissions, automatically without needing to add custom code.
In manual tracking, you also have to update event tracking code snippets every time you make changes to your website or product. This isn’t necessary with autocapture because you don’t need to constantly re-tag or edit code as your product changes over time. This reduces maintenance costs and the risk of data loss, and it ensures your analytics stay accurate even as your product or website evolves.
How does autocapture work?
Autocapture makes collecting basic user interaction data fast and simple. Mixpanel’s Autocapture is a great example of this. Here’s how it works:
- Add a single snippet of code: To get started, simply copy and paste a single snippet of code into your website or application.
- That’s it! You’re ready to start capturing data instantly: Autocapture will now track the most common user interactions, and those events will flow into Mixpanel in real time. The beauty of this approach is you don’t need to manually tag events or worry about updating your tracking code every time something changes.
Examples of data you can collect with autocapture
With autocapture, you can track a wide range of user interactions across websites and applications and get valuable insights into user behavior almost instantly. For instance, you can track:
- Page views: Which pages users visit most often and where they spend the most time
- UTM data: Which pages are driving traffic and conversions
- Button clicks: Which buttons or calls to action get clicked and how often are users converting after clicking
- Form submissions: How users interact with forms, whether they abandon them, or how long it takes for them to submit
This data can help you answer key questions like:
- How are users navigating through the product?
- Are they getting stuck in certain areas?
- Which features are being used?
Autocapture vs. precision tracking vs. codeless tracking
To understand the power of autocapture, it’s helpful to compare it with other primary tracking methods like precision tracking and codeless tracking.
Precision tracking: In traditional precision tracking, developers manually add specific tags or code snippets to track each event. For example, when a user clicks a button or submits a form, a small snippet of code runs and sends tracking data to your analytics platform. This method gives you great accuracy. It also requires writing more code upfront and maintaining it.
- Use case example: An ecommerce platform with a sophisticated checkout process needs to track the exact steps users take from adding an item to their cart to completing a purchase. Precision tracking allows them to manually tag every stage (like "Cart added," "Checkout started," and "Payment completed") and include specific properties (like cart value or product categories). This level of granularity ensures that the team can optimize each step of the funnel and pinpoint any drop-off points or friction.
- Drawback: Higher maintenance. Teams need to be diligent about tagging events and documenting changes.
Codeless tracking: Codeless tracking tools allow non-technical teams to define events using a point-and-click interface. While the initial setup might not require any coding at all, the problem with this method is it is prone to inconsistencies in labeling and tracking errors if the underlying code changes (for example, if a button element is renamed or removed).
- Use case example: A marketing team for a SaaS product needs to track user engagement across interactions like sign-ups, demo requests, and subscription plan changes. Using codeless tracking, the team can use a simple UI editor to tag events like "Sign-up button clicked" and update or add new events without waiting for the engineering team to implement changes. This flexibility lets them quickly react to marketing campaigns and product updates while maintaining control over the tracking setup.
- Drawback: Not done properly, codeless tracking can become a data management nightmare, with badly named items or events that don’t capture what you think they capture.
“Even though it looks a little different, you have the same exact problem in codeless implementation, because you still have to define events and attributes—you're just using a UI editor instead of a text editor.”
Autocapture strikes a balance between both approaches. It’s implemented with just a small amount of code, automatically detects the most common user interactions, and then captures them in your analytics platform without requiring hours of laborious manual tagging or interventions.
For most teams, autocapture is an excellent starting point because, unlike codeless solutions, it offers the flexibility of adding more custom code precision tracking as time goes on and business needs evolve.
Take a startup that’s releasing a new version of their web app for example. To get started with analytics quickly, they really only need to track user interactions like button clicks and page views across different pages. Knowing they may want to pursue more in-depth analysis later, they go with autocapture, which only costs them a few minutes of coding time to implement but can be expanded down the road.
The benefits of autocapture
Autocapture is a powerful solution because it can significantly streamline the vital process of data collection while providing several key benefits:
Time saved
Many data projects fail because teams aren’t sure where to start and get stuck with too many decisions on how to get started with tracking data. Autocapture gives you a blueprint to get things rolling, and the flexibility to customize your setup and add more events (with precision tracking) when you're ready. Not only does this let you get started quickly with an educated approach, it also accelerates your time to value.
More data coverage
With autocapture, you can gather extensive data on how users are interacting with your product. This helps you assess feature adoption, user engagement, and pain points more effectively.
Faster iteration
Because autocapture obtains so much data in real time, teams can analyze behavior, identify issues, and iterate on new features or designs faster—without waiting days or weeks for custom code to be created and implemented.
“Because these labels are applied at query time, autocapture is also very resilient to upstream changes. If a button's text changes from 'Sign up' to 'Try it now,' you can just add a new clause to your custom event.”
When you need more than autocapture
While autocapture has many advantages, there are a few extra points to keep in mind:
Managing large data volume
Autocapture’s ability to collect vast amounts of user interaction data can lead to information overload and make it difficult to filter and prioritize the most valuable insights.
To manage this, prioritize key events that align with your product goals, segment data by user types (e.g., new vs. returning users), and consider throttling or reducing data collection for less critical actions.
These steps will help you maintain a focused, manageable data set.
Ensuring privacy compliance and ethical data collection
Another potential drawback of the large volume of user data that autocapture collects is the increased risk to privacy if it's not managed properly. Look for a platform, such as Mixpanel, that doesn’t collect sensitive information by default and is built in compliance with industry best practices and major laws like GDPR and CCPA. It’s also a good idea to reach for an autocapture feature that’s easily configurable so you can toggle off data you simply don’t need—something Mixpanel also offers.
Mixpanel tip: Ensuring compliance with privacy regulations like GDPR requires obtaining explicit user consent before data collection, minimizing the data gathered to what’s necessary, anonymizing sensitive information, and implementing data retention policies.
Teams can protect user data and avoid legal pitfalls by adopting privacy-by-design principles, and using compliance features built into analytics tools.
Integrating autocapture data with broader product analytics workflows
For autocapture data to be truly valuable, it has to integrate with your broader product analytics workflows. This involves syncing autocapture data across multiple web and mobile platforms and combining it with other data sources, such as CRM systems, for a more complete view of user behavior.
Setting up automated reporting, dashboards, and contextualizing events with user-specific details will help ensure the data is accurate and actionable, and can be used to make informed product decisions in real-time.
Autocapture in action
Now, let’s look at a couple of examples of how autocapture can work in practice:
Tracking feature adoption
Your team just released a new feature in your app. With autocapture, you don’t need to manually set up a UTM tag for each page or tracking for each button click or interaction on the new feature. Instead, all that data starts flowing into your analytics platform automatically, giving you instant insights into how users are adopting the new feature.
Identifying key touchpoints
Let’s say you run an ecommerce store. Autocapture can help you identify where users are dropping off in the checkout process or encountering friction across both mobile and web platforms. By tracking interactions with forms, buttons, and other UI elements, you can pinpoint where improvements are needed, reduce abandoned carts, and increase online sales.
How Mixpanel’s Autocapture empowers teams
Mixpanel’s Autocapture unlocks a new level of efficiency for teams, allowing them to effortlessly track user behavior and turn data into insights without the heavy lifting.
Intuitive setup and customization
Setup is one of the most arduous steps of tracking user behavior data. Mixpanel simplifies event tracking by allowing teams to start collecting data with just a single snippet of code. Once data is captured, product teams can use customizable filters to quickly focus on the most relevant user interactions, whether by segmenting data by user cohorts, behaviors, or features, making it easier to derive insights from vast amounts of data.
Real-time, actionable insights from behavioral user data
Mixpanel’s intuitive, real-time dashboards (we call them Boards) make it easy to visualize user behavior trends in a digestible format:
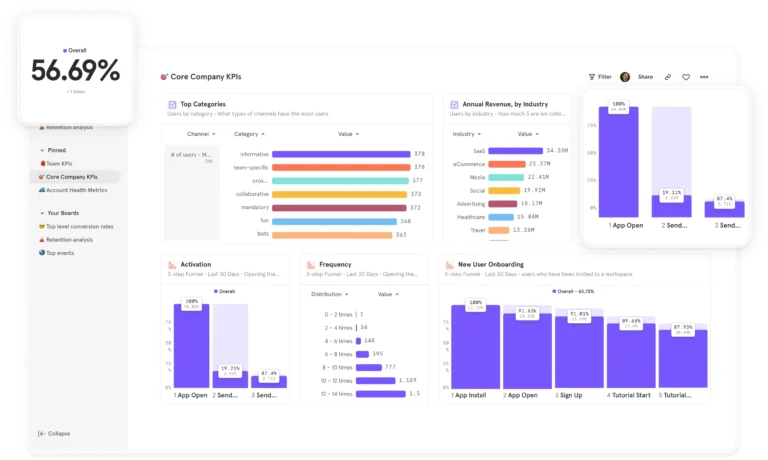
These dashboards automatically update with new data from Autocapture, helping product teams quickly spot patterns, identify bottlenecks, and measure key metrics like feature adoption, without having to sift through raw data.
Integration with product development workflows for faster iteration and decision-making
No matter what tools you already have in your tech stack, Mixpanel integrates seamlessly into existing product development workflows and systems by syncing with popular solutions such as Sprig, Productboard, and Adapty.
This aligns the entire team around the same user behavior insights and makes it easier for product managers, designers, and developers to prioritize updates and iterate on features.
Get started with autocapture analytics today
Autocapture is a valuable data collection option. Not only does it make it possible to gather user behavior insights instantly, but it also minimizes the manual effort required to set up event tracking, no matter how many different types of interactions you want to measure.Try Mixpanel’s Autocapture for free to get started with digital analytics that powers companies like Rakuten, Uber, and DocuSign to build better products based on real-time, actionable data.