

Re-build vs. buy—or how to turn a legacy tool into a new data stack

Build vs. buy is one of those “evergreen” debates. When building a data stack and figuring out its respective components, it seems like it’ll never be out of style to ask: Wouldn’t it just be easier to buy?
But there’s another, similar scenario that’s much less talked about even though it’s probably equally as important and common: RE-build vs buy. When you have a legacy product you don’t want to totally get rid of but also no longer functions the way you need it to for the way the market is evolving, what do you do with it?
That’s indeed the question we were asking a while back at Dyspatch, where I work as a Senior Product Manager (formerly, Product Designer).
For context, Dyspatch is an email creation and management platform. We had a bunch of data stuck in an older internal tool and we were trying to figure out how to make the most out of that data.
Here’s what we learned in this process and how we ended up turning an in-house tool into a new data stack.
Making our old tech future-proof
“Future-proof” is a buzzword for a good reason: Things in the data and IT world change so fast that if you don’t design your architectures for the future—and by “future” I mean only two to three years out—you are setting yourself up for failure.
If you want to move fast and are in a similar situation to us as a smaller SaaS team (currently around 40 people and growing), buying makes a lot more sense than building because it allows you to stay focused on your product offering while quickly being able to reference data to help make decisions. In our particular situation at Dyspatch, we had already built something before realizing we needed more functionality. So what was the right next move?
The in-house tool we’ve been using to gather customer behavior data does a great job at that, but it doesn’t do much more. So, when we decided we wanted to add analysis to our stack, it became a question of: “Do we invest time, money, effort, and everything else into that while then taking away those same resources from the product?”
Our solution was to connect our internal tool to Segment (for data collection and direction) and Mixpanel (for product analytics). Not only did this create a single source of truth for our data and funnel it into a powerful analytics platform, but, thanks to the new data stack we’ve built, it also created flexibility to send our data wherever else we decide we need it go—today or in the future.
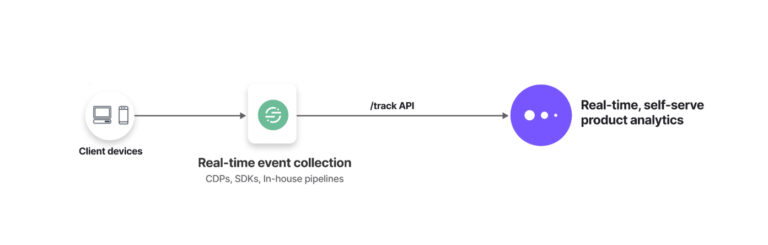
Saving time for product and engineering
For implementation, the choice to buy and not build (or re-build) saved us engineering time: Connecting our data tool to Segment and then to Mixpanel took only a handful of hours of SDK and API work. But beyond that, the fact that we were able to keep a tool our product people knew well at the front of our new data stack spared us onboarding time, too.
But of course, adding extra functionality was the big, long-term time-saver. Again, when it came to our internal tool, it was more about collecting data at a user level—data that would act more like breadcrumbs that we could reference if something went wrong. The only way to do any kind of analysis from there was to commit considerable time and effort to do one-off queries. But now, by using Segment to direct that data to Mixpanel, we’re never more than a few clicks away from getting rich analysis reports that give us a better understanding of user behavior.
You also have to consider future maintenance—the bigger the product, the more maintenance, people, and budget required to keep it working properly and on track. With buying, you have a team behind you maintaining the product, and you’re paying a fraction of the cost and your team can stay focused on what’s paying the bills.
If we’d had to build an internal solution, we would’ve had to slot it into our roadmap, which means it would’ve been continuously deprioritized against new product features and would’ve been at a high risk of never reaching its full potential or providing the tools we needed for the business.
The power of product analytics
Even though adding Mixpanel for product analytics to our new data stack has given us an easy way to capture overviews of what our customers are doing, it’s unlocked so much more functionality beyond that.
We’re using cohorts to better understand the behavior of different customer groups at once, information that gives us clues about what we need to address in the product for which users. And no matter how many different ways we cut our user behavior into groups, it can all still be viewed in cumulative totals in a variety of ways, including the typical (but very important) across-the-board numbers like monthly active users, daily active users, popular actions, etc.
We also use alerts to stay on top of account health. For example, we can keep an eye on if a customer has removed several users from their organization by setting an alert to define a threshold and have it notify us if that threshold is reached.
From an account management perspective, this has been useful on several occasions to kickstart conversations with customers to ensure needs are being met or confirm that it wasn’t an accident.
When we were only using our own tech, we would’ve had to manually review this daily or set aside engineering time to develop a solution. But with Mixpanel we’ve been able to do this without having to code anything.
All in all, deciding to breathe new life into our old in-house data tool wound up being the most painless, efficient, and productive way to get more functionality out of our data workflow. I’d recommend any company in a similar situation to give it a shot.
About Ryan Stinson
Ryan is a Senior Product Manager at Dyspatch, a leading platform for email creation and management. As a former Product Designer at Dyspatch, Ryan draws on years of experience leading UX/UI design teams. When he’s not developing new, innovative solutions for email, Ryan can be found hanging out with his wife, two Pomeranians, and two ducks.