

Choosing the right analytics data architecture tech: A step-by-step guide

Every tool in your tech stack has two sides: what goes in and what comes out. With a tool like Mixpanel for product analytics, that includes event data (what’s happening in your product) and your team’s analysis of that data.
As with any implementation, teams have to think about the “data in”—or the ingestion method to collect data and send it to Mixpanel. There are certainly short-term things to consider, like getting a tool in the hands of team members as quickly as possible to achieve some quick wins. But the best companies also look forward and future-proof their data architecture by making decisions that work for their company stage, analytics maturity, and current data collection processes.
At Mixpanel, we prefer to deeply understand a customer’s analytics use cases, current tech stack, and organizational norms in order to have productive conversations about the data collection options available and form an opinion about what would be best for their specific needs. Internal discussions have to weigh not only what’s best for using Mixpanel, but the organization as a whole, including all team members who might use the tool in the future.
If you haven’t read our blog covering the organizational questions companies should ask themselves before diving into the tech and tools part of building a data architecture, you can check it out here.
Selecting an implementation method
Customers often start with a tool like Mixpanel for both event collection and analysis. But as they grow and their data needs mature, this event data is needed for non-analytics use cases, like personalization and experimentation. They may also develop more constraints around data governance, security, privacy, etc. At that point, it often makes more sense to collect the data outside of Mixpanel, in a centralized “source of truth” repository that can feed into multiple tools in the tech stack and be governed in a single location.
Implementation methods can and do change throughout a company’s lifecycle. A mature company like Uber or Yelp trying to democratize self-serve analytics has different needs than a small startup trying to capture behavioral event data for the first time. Our philosophy is that we’re open to whatever method is best for a customer to move forward with data collection for their organization, provided it feeds Mixpanel with trusted behavioral data.
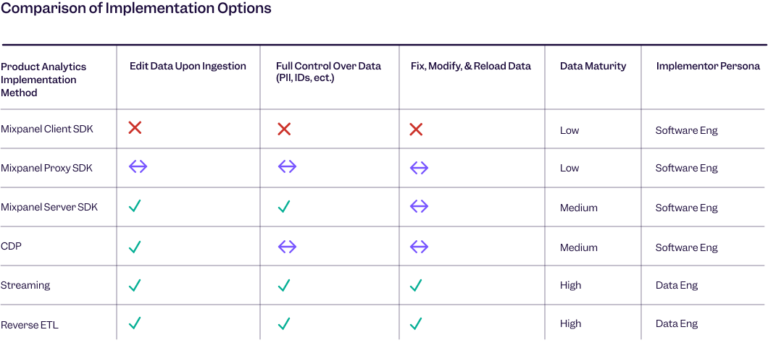
A table showing how the different implementation options measure up. An ❌ means a feature isn’t supported, while a ✅ means it is and an ↔️ means it’s possible with some customizations.
Product data is often a combination of transactional data that is stored in your application database (such as MySQLPostgres) and clickstream data (browser and/or mobile apps) that is tracked through client or server-side SDKs.
When identifying the best source of data for Mixpanel, we focus on 1) availability (can we get the data into Mixpanel?) and 2) reliability (can team members trust the data?).
Despite there being many different options, there are similarities between customers that drive them to choose specific implementation approaches. To help guide your decision, we’ve rounded up some key factors we discuss with customers and the impact of different implementation decisions.
Does your company have a source of truth?
At the heart of analytics is accuracy and reliability. If your team can’t trust the data, they won’t rely on the output of product analytics to make decisions.
If you’re coming from another method of analyzing data, you’ll need to replicate what team members see in other systems: rooted in the same source of truth. Otherwise, team members will compare Mixpanel to the “old way.” If there are discrepancies, they’ll lose trust and revert to the old habits for generating analysis—unless it is widely accepted throughout the organization that the data was unreliable and problematic and you’re looking to Mixpanel for a fresh start.
Transactional systems, such as MySQL, are the most trustworthy source of data since they’re designed with consistency and reliability in mind. Building on that foundation, a data warehouse is the most scalable and effective way to store large amounts of transactional data that you can later transform into events.
If your team already has a data warehouse or data lake that holds your source of truth (even if only partially complete), then you should start there. No need to reinvent the wheel. When possible, use the data warehouse to model and push events to all of your tools. This is especially true for data enrichment that is done post-ingestion.
Is your company built on behavioral data?
For some companies, behavioral data is the core of the business model. Take Uber, for example. Real-time pricing and driver availability are based on collecting and processing massive amounts of behavioral event data (and quickly). The analytics engineering and/or data engineering teams have likely built and maintained an entire data pipeline, and that can be the source for Mixpanel.
These teams typically come to Mixpanel with problems of data democratization, or trouble being able to quickly and easily generate insights from their data. They face internal bottlenecks, such as relying on engineers or analysts for data requests. Data collection isn’t the problem; getting data into the hands of people who can make decisions is.
At the opposite end, we also work with companies where behavioral event data isn’t core to their business. And that’s ok! If the data already exists in a source of truth, they can use a reverse ETL (or rETL, which stands for reverse extract, transform, load) tool like Census to model entries into their database. The entries might be a signup or a purchase–actions with a user, timestamp, and properties (metadata)—which are used as events in Mixpanel. This allows these companies to get accurate data quickly. They can also leverage the historical entries stored in the data warehouse.
Do you already have a CDP, event stream, or reverse ETL tool?
If you already have an event stream, CDP, or reverse ETL in place, the hard work of collecting data has already been done. It is ready to be consumed by downstream destinations, and you can use one of these options to send the data to Mixpanel.
At a minimum, you should leverage these tools for transactional data. You should also use these tools for data that is critical to business operations and therefore needs to be extremely accurate (such as signups, purchases, and churned customers).
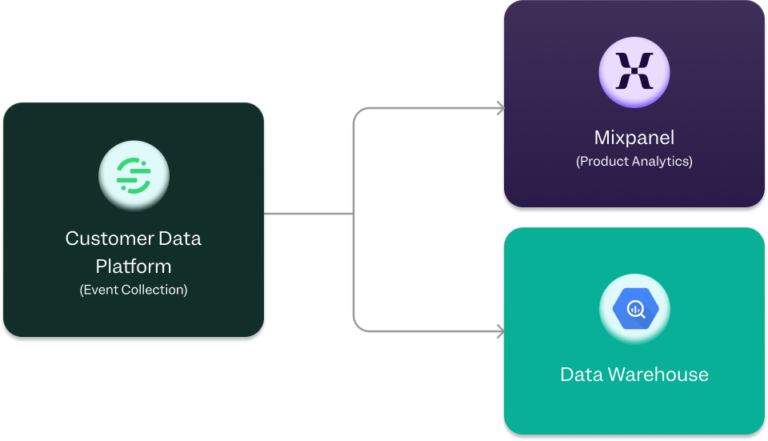
Customer data platform (CDP)
As your data needs evolve, you might start to consider options like a customer data platform (CDP) like Segment. With a CDP, you can instrument tracking code once, route through a single source, and then forward the data onward to other tools. And while a CDP adds another tool to your tech stack, since it is a central repository from which data flows, you can easily change downstream providers if needed.
You can use the UI for managing data flow and transformations to enrich/enhance the data—rather than relying on an engineer to maintain a pipeline with event streaming. Depending on the platform, you may face limitations on the transformations and enrichment that can be done compared to what can be done in your data warehouse.
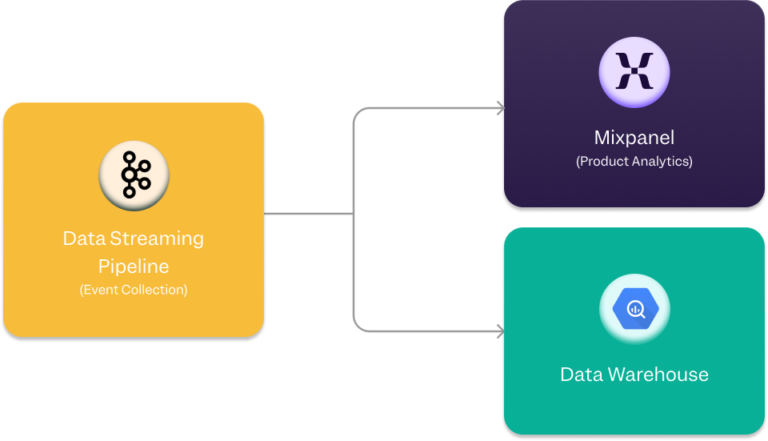
Event streaming
If you’re a more mature data organization and already have set up your own data pipeline, we support event streaming to Mixpanel.
In this approach, you position Mixpanel in your ingestion pipeline and send data to us as it is received. It is low maintenance because you are able to leverage your existing infrastructure. There is also a high level of trust in the data since it has already been validated and cleaned. A centralized data team continues to be responsible for data governance.
The only downside is that there is no enrichment of the data: It is sent as received. You’ll need to transform the data so that it can be used in Mixpanel.
Reverse ETL
For the most mature customers, using a reverse ETL (rETL) tool like Census allows for maximum flexibility with your data needs. Instead of collecting data via a pipeline and forwarding to Mixpanel, rETL allows you to take your existing data warehouse data and model it as events.
Like event streaming, you’re also leveraging existing infrastructure, relying on high-trust data, and maintaining centralized data governance. But it’s another tool in the tech stack and requires maintenance via SQL to enrich, model, and transform the data. Both event streaming and rETL will likely require involvement from your data engineering team to implement.

Do you have any clickstream data?
Clickstream data, or data about the user journey of a user, can be collected with high levels of accuracy. You may already have clickstream data in your event stream, CDP, or rETL tool. If so, you should rely on this existing data for Mixpanel. If it doesn’t exist, you can consider adding it to your data collection strategy.
If you don’t have clickstream data and want to use Mixpanel to help with data collection, we highly recommend that you utilize server logs or a server-side implementation to generate events from clickstream activities. Server-side data is much more accurate than client-side data. This will allow the most flexibility in the long run as you scale your implementation.
Mixpanel server-side SDKs
With server-side tracking, events are generated by your server and sent to the Mixpanel API as part of your application flow. For example: a user loads a web page, and a request is made to your web application server. You can create a “Page loaded” event in the code and send it to Mixpanel from your server.
Server-side tracking doesn’t require any additional infrastructure. The data is consistent across platforms, and it’s easy to fix any integration issues.
Because the tracking sits on the server, you’ll need additional code to maintain this approach over time. It can also be harder to track client-side actions and requires some custom code to track anonymous users across devices and persist property values across requests (what we call “Super Properties”: event properties that you can register once to automatically attach to every Event you’re tracking).
Is it feasible to add a proxy?
Most smaller customers get started with Mixpanel using our client-side SDKs. These SDKs are easy to implement into your app so you can start tracking live behavioral data to Mixpanel, and they require no additional infrastructure. You can track anonymous users and requests and persist property values.
But over time, this data can be hard to manage. Web tracking is often unreliable due to ad blockers, and mobile tracking is tricky since iOS and Android diverge code with new versions. Because of these gaps, your team members may not trust the data in Mixpanel as much over time. It is also harder to fix issues with the integration, particularly on mobile, since you’ll invariably have users that never upgrade the app. Old versions of the app can send incorrect or broken data that you may have already fixed in newer versions.
Mixpanel client-side SDKs plus proxy
You can improve client-side SDKs by establishing a proxy between the client and Mixpanel—and we highly recommend this for client-side implementations. This will minimize issues with data accuracy and make your implementation more flexible in the long run since you can leverage the proxy to modify tracking over time.
With a proxy, you can easily track client-side actions and state. The data is less susceptible to being blocked by ad blockers, and you’ll have more control over the data you’re sending to Mixpanel. You can also filter and clean the data as needed.
Proxies require additional infrastructure, and your team will be responsible for building a proxy server. You’ll need to write code for all the rules that transform and maintain the data. We often think of proxies as a step toward a modern data architecture rather than a solution.
Making the right decision for your company
As we talk with your team during implementation and throughout our relationship, we’ll recommend an approach that 1) ensures the data is trustworthy and 2) captures key use cases.
We know that event data is used for more than just analytics, and teams want the best tool for the job, without vendor lock-in. That’s why we support decoupling event collection from the tools where the events are used.
Ultimately, the method for implementing product analytics is unique to each customer and their current data stack. There’s no right or wrong, and we’ll walk you through all of the above scenarios. Our recommendations will be based on what makes the most sense for both Mixpanel and your organization as a whole.
At Mixpanel, we ensure you’re set up for success with a data architecture that can support product analytics. We provide free onboarding to any company on an enterprise plan. Contact us for more information.