

5 questions to ask yourself before planning your data architecture

Which color is better: green or red?
Which time of day is better: morning or night?
Which flavor is better: sweet or sour?
The answer to all of these questions? It depends. There’s no “right” answer. And the same is true for deciding on a data architecture when using an analytics tool. It depends on your existing data (availability, structure, format, and other factors) and what you need from analytics.
In the case of product teams, you should be trying to do two things: collect behavioral data and analyze it. If your tech stack includes an analytics tool (like product analytics, business intelligence, or other tools) or you’re looking to add analytics capabilities in the future, you might be thinking about your existing data architecture.
It’s a valid consideration since, ultimately, any tool you use will only be as good as the data that feeds it. And since there’s no one-size-fits-all approach, we’ve rounded up some key things to think about within your own team when deciding on a data architecture for your analytics needs.
What role does data architecture play in your tech stack?
Data architecture is more than a support structure for your product. It’s an important strategic asset that can impact product decisions, responsiveness to product issues, and overall scalability. Any tools you use will rely on choices you make about your data architecture.
How you design, organize, and manage the structure and flow of your data creates the foundation. It involves the data and systems, yes, but it also hinges on people, processes, and use cases.
1. How are you collecting data?
Tl;dr: Get as close to your existing source of truth as possible. If you have to create new data via client-side SDKs, use a proxy.
Most companies collect and analyze data from multiple sources, so at the core of data architecture is the question: Do you have a source of truth?
Your source of truth should represent data that is clean, trustworthy, and up-to-date. It typically includes data collected from multiple sources and is stored in the data warehouse or data lake where it is queried for analysis.
Knowing that you have a centralized source of truth versus multiple sources of data is important to architecting your data for analysis. If you have disparate sources of data, they might seem accurate on their own but would need to be unified and verified for accurate analysis. Once data is sent from these various systems (that seem correct on their own) to a product analytics tool, discrepancies will appear between data that comes from different systems.
It’s like putting together two different puzzles. On their own, the pieces go together perfectly. But when you’re trying to create one giant puzzle from two different sets, the pieces won’t fit together unless they’re the same shape and size. There are still ways to get to a full picture, but it might take some massaging of the pieces.
So let’s look at potential sources for your data and how they fit with an analytics tool.
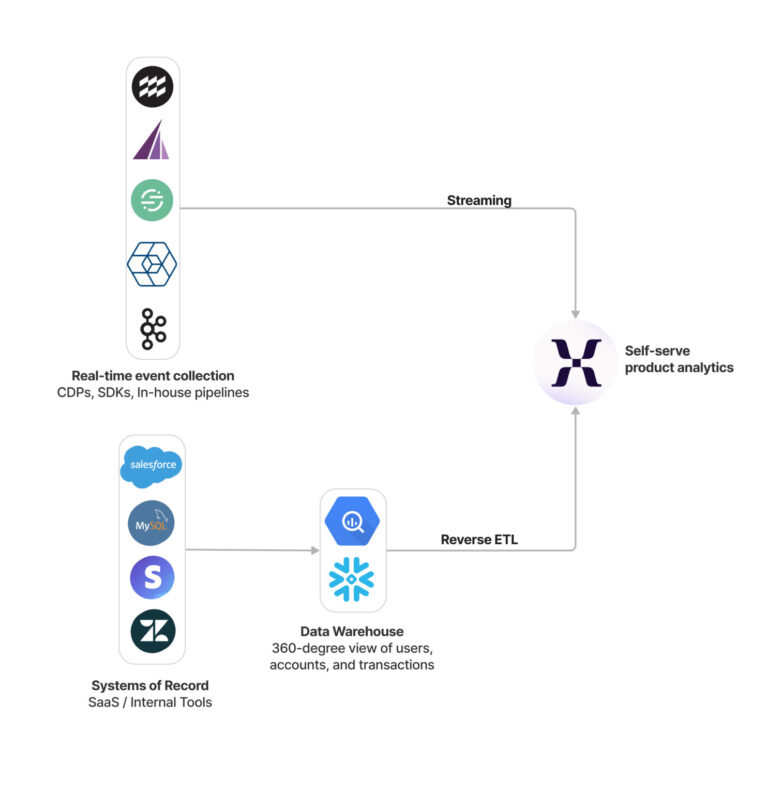
Option 1: You already collect data somehow, somewhere
If you’re capturing, processing, and storing user actions or events as they occur, you can format this data so it can be used for self-serve analysis in product analytics. Many teams do the hard work of setting up a trustworthy data collection infrastructure only to fail to unlock its power in self-serve.
In terms of options, companies who depend on data to run their business (for example, Uber surfacing surge pricing to users in real-time) typically decide to rely on their existing event streaming data infrastructure to add product analytics as a destination. This allows users to run analysis on the same actions that power the application.
Data warehouses are the most scalable and effective way to transform transactional data into events. For those who have data in a data warehouse that would typically require an analyst to write SQL and produce reporting, you can natively import that data into Mixpanel via Warehouse Connectors. Your analytics resources can model the data and create a source of truth for your company and then push this modeled, verified data to Mixpanel for self-serve analytics. Additionally, you can leverage a reverse ETL tool (reverse extract, transform, and load tool or rETL) if your current data warehouse is not supported by Warehouse Connectors today. In these setups, data from your source of truth is imported into your event analytics tool so that queries running in either system match the other. You can also send more types of data via your warehouse, such as marketing or revenue data, in addition to product actions.
As another option, if your company has already implemented a Customer Data Platform (CDP) like Segment to collect and manage behavioral data, you can add product analytics as a destination. Do note that the data format and needs of product analytics may differ from other destinations, but you can easily integrate an existing data infrastructure. This setup allows for quick integration into a product analytics tool with data that is already being sent to downstream systems and should be familiar to users within your organization.
Option 2: Data you need to create: CDP, server-side SDKs, client-side SDKs
In other cases, you might not be capturing data you need in order to understand the user’s journey through your site or app. This is especially true when you might be just getting started with analytics, as adding tracking for all touchpoints across a user’s journey is done iteratively over time.
If you don’t need to connect to many tools, or similarly don’t have the need for a CDP, we recommend server-side SDKs. Tracking data on the server is more trustworthy than client-side tracking as client-side tracking is susceptible to data discrepancies due to ad blockers, end-user privacy settings, etc. Using the server, you can control what to track and when with accuracy.
If you’re brand new to product analytics, many customers investigate CDPs first before proceeding with other options. CDPs allow you to implement a single SDK for data collection that feeds any number of destinations, making data collection for many tools easy and simple.
Lastly, client-side SDKs are very easy to get started with tracking new data. But they often fall short in terms of scalability as they are inaccurate (ad blockers), irreversible (on mobile), and inflexible (cannot modify or fix errors). If you must get started here, you should definitely use a proxy to get going.
Option 3: Hybrid approach
The good news? You don’t have to choose a single method of data ingestion.
For example, you might be thinking about your future data stack just as Mixpanel is being implemented. You might opt to track a number of events via Mixpanel SDKs to prove value quickly. But also wonder about how to best scale your data architecture over time.
If you’re just getting started, we would recommend a hybrid approach. Specifically, it makes sense to use a Mixpanel SDK option to capture new client-side behavioral events and a connection to a data warehouse to capture key transactional events.
This approach ensures that the data is trustworthy and useful, based on a dual goal of getting Mixpanel in the hands of users quickly while building for the future. Individual product teams can define additional behaviors to track that iteratively build on a strong foundation. It also allows for flexibility over time, where you can evolve transactional data as your data maturity increases.
Over time, you can then decrease your reliance on the SDK. This allows your company to continue to use Mixpanel to answer important product questions today, while also planning an approach for future needs.
2. How will the data be used?
If you’re working on a product team, hopefully you’re thinking about tools for collecting data and analyzing it. That’s a great place to start. To have a modern data stack, you need a combination of tools that can store, process, and analyze your data to meet business goals.
But as organizations mature, this data might be used for non-analytics use cases. You might branch into personalization or marketing automation, relying on the behavioral data collected from your product.
Or, you may have more constraints around governance and security, especially if you’re in a regulated industry or have clients across the globe. Everything from compliance requirements to best practices may change.
You may even find that growing your analytics usage among different teams will alter your approach to data. That source of truth you had previously identified: Does it still exist once you’ve expanded to other teams?
As you consider a modern data stack, you need to keep these things in mind: not just the use cases for today, but the potential for growth. Many forward-thinking teams want to approach data architecture with a “built to last” mentality, but the best data architectures are those that change over time. They’re designed to blend and scale with new systems and new technologies over time.
While there isn’t one “right” approach to data architecture, the best systems are flexible. You can choose and integrate new tools for your future vendor needs without being tied to one vendor. Your organization’s data needs will change over time and you don’t want to find yourself married to one architecture that doesn’t “fit” with new tools in your tech stack.
3. What standards already exist?
You’ve got your eye on a flexible data architecture that can grow with your organization. Makes sense to implement best practices—right?
Product teams often inherit data structure decisions that came long before them. You can’t change those; you have to find a way to make them work for your use cases. You can’t re-engineer the software, and you’re not going to convince engineers to do new things that go against standards that have been in place at the company for a long time.
At Mixpanel, we believe that you shouldn’t go against the grain. You want to build on top of what you already have.
You’re considering your data architecture through the lens of how it will work with your other tools. When teams use analytics tools, they’re often given a list of best practices for things like “naming events” . But if those best practices don’t align with how your team already understands event data internally, it will cause friction when you’re trying to add a new tool into the mix.
You can be aware that your internal standards might cause problems with analytics down the road—and prepare to address them. But otherwise, we recommend going with standards that everyone on your team will understand.
4. What resources are available?
Whether you’re thinking about adding a new tool to your tech stack or considering changes to your existing data architecture, your dreams can only be as big as your available resources.
Connecting your existing data architecture to a product analytics tool like Mixpanel requires you to choose an ingestion method. If you opt for Warehouse Connectors, you need someone with access permissions to your data warehouse, likely from your data or analytics team. If you want to use data streaming or rETL, you’ll need an engineer to write code to make the data accessible.
You have to weigh making the tool and data available to your internal product teams versus planning for every contingency—that may or may not pan out.
Much like the hybrid approach to your data architecture, there’s an “in-between” option for adding analytics tools to your tech stack. We advocate starting with two or three events to test the architecture. You can rely on these quick wins that use some of the data that’s easy to work with today, while building toward collecting better data in the future. Eventually, you’ll have a system that supports self-serve analytics because the data is readily available to your product teams.
Ensure the quality and relevance of the data you need are clear to your engineers. The goal isn’t to collect all data within an analytics tool, but the information that has a direct impact on your business. You can also use data governance best practices and assign a data governance owner who can run regular health checks against the data.
If you can answer the question, “Why does this data matter?” you can focus your team’s resources on adding the right data from your existing architecture or via new ingestion methods.
5. Can you build excitement for data architecture?
Perhaps a few people get really excited when they think about data architecture, but the reality is that it often sits “in the middle.” Engineers want to build new things, and product teams want to get something into the hands of users. Data architecture can require a lot of complex factors, and (like we mentioned earlier) it’s often inherited.
But when you’re adding a new analytics tool to your tech stack, there are ways to get people excited about the possibilities. People want access. Sometimes they’ve been waiting for months (or longer) for a tool like Mixpanel. They want to get their hands on a self-serve tool and give it a try in real life, with real data.
Building on that excitement might mean taking the path of least resistance with data ingestion. Using your existing data architecture, you can get started with the data that’s immediately available and a low lift for your engineering team. The data might have some issues, but at least your product teams can play with different scenarios.
And on the flip side, your engineers might be relieved that they no longer need to respond to requests for analytics and data. They’ll see the need for more democratized data going forward—and that, in turn, can influence how your company thinks about data architecture as a whole.
Excitement is a key ingredient. Keep that in mind.
Keep your eyes on the future with your data architecture
We believe that a great analytics setup is three things:
- Trustworthy: You can trust and understand the data.
- Comprehensive: You can load Mixpanel with all the data you need for analysis.
- Maintainable: You can set up, maintain, evolve, and scale the system with minimal effort.
All three of these components rely on the data architecture and the decisions that you make.
We also know that a tool has to work for a team, which is why we don’t advocate for a single approach to data architecture. We’d rather talk with teams and make recommendations based on their resources, how they plan to use Mixpanel, and how they’re collecting data today. It also means looking forward and having conversations with customers about the future and changes that might be necessary.
No matter what tool you’re adding to your tech stack, it should work for your team and make your lives easier.
Integrating product analytics into your tech stack doesn’t have to be a full-time job—let Mixpanel help. We offer free onboarding to any company on an enterprise plan. Contact us to learn more.