

Introducing query-time sampling: Fast, lossless user analytics at scale

Interactive-speed analytics accelerates the rate of product innovation. However, achieving sub-second latencies at the scale of our largest customers, who track billions of user interactions a day, can be expensive. In pursuit of fast AND cost-effective, some of these customers were willing to sacrifice accuracy. About eight years ago, we addressed this demand by building ingestion-time behavioral sampling.
Ingestion-time behavioral sampling
One could sample data down to X% by dropping all but X% of events at ingestion. However, sampling randomly this way fails to preserve the full event stream for any given user, which would make our core behavioral analytics (e.g. funnels, retention, flows, cohorts) less reliable.
To solve this problem, we sampled at the user level. For a sampling rate of X%, we would keep full event streams for X% of users. This way, if a user was in our sample, we guaranteed that we had all of their events. This allowed us to, for example, reliably determine whether the user completed a funnel. Notably, all events for the remaining (100-X)% of users were dropped at ingestion. At query-time, we scanned the data and extrapolated based on the minimum-observed sampling rate (carefully accounting for changing sampling rates).
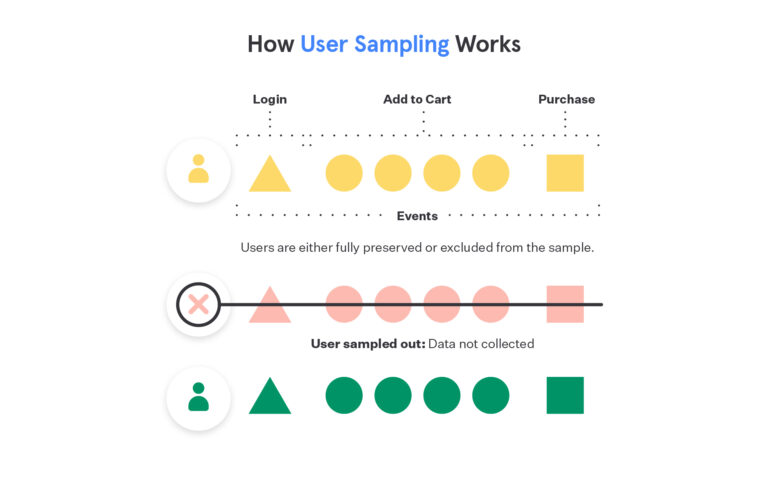
At the time, this seemed like an elegant and transparent way to provide interactive-speed analytics at reasonable cost, without compromising on analysis quality. Indeed, after we built ingestion-time sampling, other product analytics solutions followed suit, and this became the industry standard for “scalability.”
Why ingestion-time sampling will let you down
After years of working with large customers using the aforementioned solution, we learned of the pitfalls of this approach.
1. It drops data
Consider the following use case. You receive a support ticket from a disgruntled user. The first step to resolve this is to analyze that particular user’s journey through your product, and Mixpanel is just the tool to do it. Unfortunately, if that user falls outside your sample, you’re totally out of luck, because that precious data was dropped! It’s particularly frustrating because the details and complexity of sampling are hidden from you; if you have some portion of your data sampled at 5% and another with the full 100%, queries spanning those two pieces of data must downsample to the lowest sampling factor seen (in this case, 5%). This, rightfully so, frustrates and confuses consumers of this data, which leads me to the next pitfall.
2. It erodes trust
Many of our sophisticated customers use Mixpanel in conjunction with a larger data stack. We built our flexible export pipeline to make this union seamless and reliable, guaranteeing a consistent view of data between their product analytics tool and, for example, their data warehouse. While we do export sampling metadata along with every event, the onus is on the end-user to apply upsampling correctly in the data warehouse; failure to do so results in mismatched data and loss of trust.
3. It reduces messaging reach
Our customers often use the cohorts they build in Mixpanel to target specific users for campaigns. A common use case would be running a promotion for new users. However, if you sample down to 10%, such a promotion can only ever reach 10% of your new users, drastically limiting its efficacy.
4. It weakens A/B test significance
A/B tests allow data-driven enterprises to apply the scientific method to product development. However, the value of testing is limited by the amount and quality of data collected; sampling means that you can only run tests on the random subsets of your users that you’ve sampled.
Hacks to get around this exist, such as whitelisting your A/B test groups from sampling, but these too are problematic. First, you need complex logic to reason about your sampling in external systems (was this user in the sample or whitelisted as part of an A/B test? Would they disappear from your sample if they stopped being in an A/B test?) Second, if you run dozens or hundreds of A/B tests, you will end up whitelisting a large percentage of your user base… paying the complexity tax, without the cost/speed benefits of less data!
5. It is irreversible
This is the worst pitfall of all. When a customer inevitably encounters these pitfalls and decides to disable sampling, their change only applies from that moment forward. All historical data outside of the sample set remains lost.
Moving on
After learning these lessons the hard way, we decided to deprecate this approach to sampling entirely. While sampling is often touted as a “solution for scale,” ingestion-time sampling fails to scale because it irreversibly drops data.
This still left the problem of improving performance for large customers. If only there were a way to use behavioral sampling to solve this problem without dropping data…
… turns out, there is.
Introducing query-time sampling: beat the tradeoff!
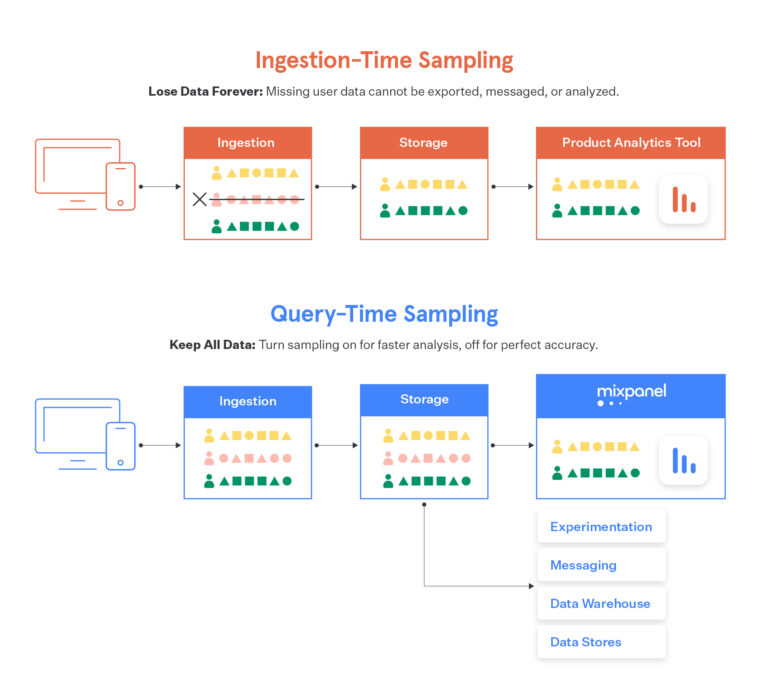
We’re thrilled to announce Query-Time Sampling, a novel feature which provides the speed of the ingestion-time approach while keeping all of your data intact. Here’s how it works.
We ingest and store full, unsampled event stream data from all our customers. When running a Mixpanel report, a user can flip a toggle to enable sampling. For each report they run with the toggle flipped, our query engine will select a 10% sample of users for analysis, run the query on the events for that subset, and apply upsampling to adjust the results. For transparency, we clearly annotate the results with the sampling rate. This produces the same results as ingestion-time sampling of 10%, except losslessly since it’s done completely at query-time. Flip the toggle on for fast, approximate queries, and off for perfectly accurate queries… it’s that simple.

Behind this simplicity lies years of investment in our core infrastructure to become the most scalable user analytics solution, period. We migrated our database to Google Cloud, and in the process, de-coupled the relatively inexpensive storage tier from the expensive compute tier that can query subsets of users on-demand. We made these changes in conjunction with our new user-centric pricing model to better align price with value for our ever-growing customers. The bottom line is that we’re built to scale with you: track as much as you want per user and we’ll ingest it, store it, and let you query it on demand!
Query-time sampling will be available across our core reports for eligible Enterprise customers over the next few weeks. For more information, please refer to our documentation!