

Product analytics and the data warehouse: A long road to a perfect pairing

For years, the data warehouse has been emerging as the central place for organizations to store and use their data. And yet for the longest time, product analytics tools have avoided the data warehouse and instead used clickstream event data. But things are changing.
- Product analytics is now one of the most important subsets of the analytics universe: Companies need to know what’s going on with their users so they can improve things.
- There’s a well-established world of product analytics tools (like Mixpanel).
- Historically, these product analytics tools have worked through clickstream data, i.e. events and logs directly from your app.
- But increasingly, the data warehouse is becoming the center of data operations (and the source of truth) for companies and their data.
As the data warehouse becomes solidified as the place to be, we’re starting to see product analytics tools shift to get ahead: Mixpanel’s new Warehouse Connectors launch allows you to bring data from your data warehouse into the tool alongside clickstream data. So I'm going to zoom out and cover what this means, why it’s important to understand, and what it means for product analytics (and analytics in general).
Basic background: What is product analytics and why is it important?
If you’re reading this on the Mixpanel blog, there’s a chance you already have a good grasp of what product analytics is and how it works. (I’ve also covered this in my newsletter in the past.) But to reiterate a bit here, product analytics helps product teams (and really anyone at your company) understand what users are doing in your product. The importance of that reverberates widely across an organization.
Good product analytics usually starts with a question. Some questions might be specific:
- What percentage of our users are utilizing this new feature?
- Do users engage with our onboarding screen or just skip it?
- Does anyone actually use the new dropdown?
But some might be broad:
- What are our most popular features?
- What screens are users finding confusing?
These kinds of questions are fundamental to the work a PM does. Trying to improve a product with no visibility into how users actually engage with it is like trying to make a negroni with vodka: It’s a useless exercise and you’re going to end up disappointed. You can get even more granular: A/B testing can give you extremely concrete answers to the kinds of questions that PMs of yore would have killed to answer.
But it’s not just about PMs. We live in a product-centric world: (Mostly) gone are the days when a charismatic salesperson at a company with a bad product can take someone out for a round of golf and close a deal by sheer force of will. Whether product-led growth (PLG) or otherwise, having a great product has become table stakes. So product analytics, in a sense, is really your whole company’s analytics. It’s much bigger and more important than just “the numbers that our PMs check.”
The sum of the answers to these product analytics questions sometimes gets organized into funnels. A funnel is like a (very) reductive view of the journey that you want your users to take. It has several stages that you expect your users to go through, and you hope (🤞) they get all the way to the bottom.
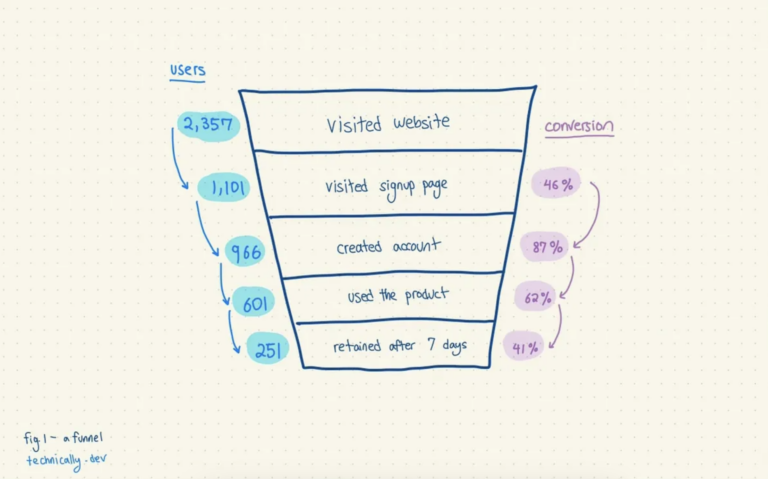
So where do the answers to these questions—and numbers in that funnel—actually come from?
Product analytics tools grew up on clickstream data
To understand how product questions get answered, we must first take a brief educational detour at clickstream data. Clickstream data is all of the events that your product generates when users do stuff. Things like:
- Page views
- Button clicks
- Dropdown selections
- Dragging something around…
- …whatever people do in your product
Whenever a user does one of these things, assuming your engineers have set things up right, a bunch of data gets generated about who did the event, what it was, and any relevant context. If you’re using a tool like Segment to send around these events, here’s what a sample one might look like that fires every time a user saves changes to their profile:
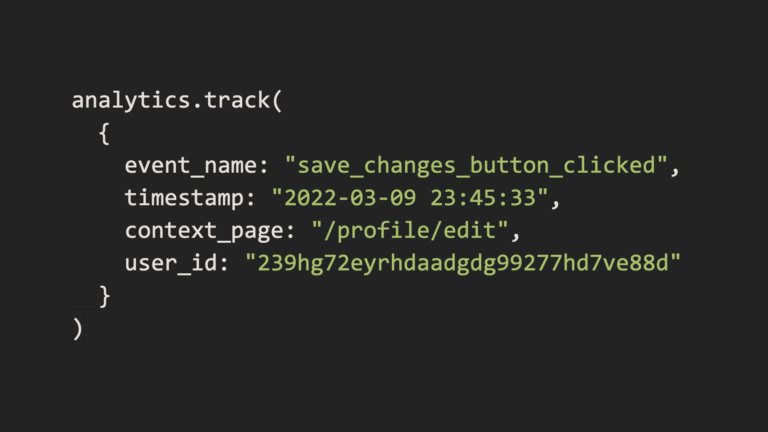
For most situations, any individual one of these events is mostly useless. But when you piece them together, you can understand what users in your product tend to do and why. But there are tons and tons and tons of them, and you need to sift through and aggregate them for them to mean anything.
In a sense, you can think of clickstream data as a very different character in our story than the data warehouse. The warehouse is where data teams organize these events into meaningful information and combine them with data from tools like Stripe, Salesforce, etc. Everything in the warehouse is manicured and pristine. Clickstream events are like the lower-level, more product-specific point of view.
Product analytics moving to the data warehouse
Historically product analytics tools have been built primarily on clickstream data. They did not integrate much with the data warehouse and instead do their own aggregation, calculation, and manipulation of the raw events that you send to them.
But why? Why would you want to use raw clickstream data and do the hard work of making sense of it in your own tool instead of using the nice, clean tables in the data warehouse that the data team has already curated? Two reasons:
- The cloud data warehouse is a relatively new thing
This is where that history lesson earlier comes in. Data warehouses weren’t always like this. Mixpanel was founded in 2009, three years before Snowflake. Most product analytics tools grew up in a world where few companies had cloud-ready data warehouses full of pristine, comprehensive data that was easy to query. They were heavy, slow, on-premises, and the purview of mostly larger companies with major analytics use cases. You couldn’t just “integrate with them” in a few steps. So instead, product analytics tools went straight to the source.
- You lose fidelity when you aggregate
When data teams do all of that nice rolling up of events data in the warehouse, you necessarily lose the granularity that events give you. Back to our “save changes” example earlier: If the data team rolls up that event into an aggregate that counts how many users save changes to their profile every day, you’d get a nice, easy-to-read and query table like this:
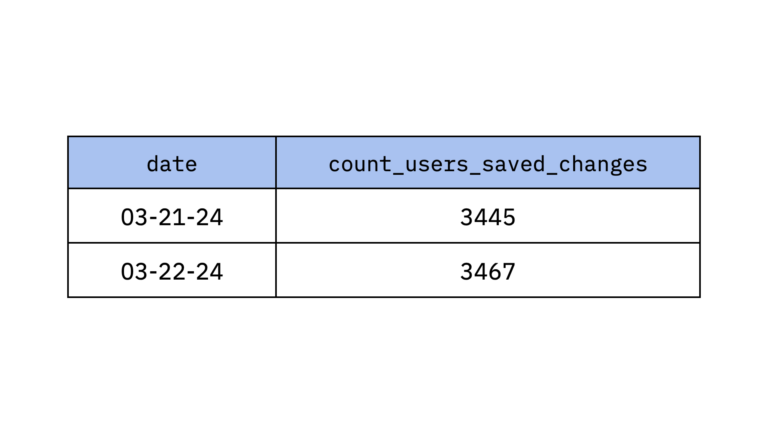
But if you had a question that went deeper—like what time a day does this happen the most, which types of users tend to make profile changes, etc.—you lose that fidelity in the aggregation. Product analytics tools are all about giving you the ability to dive deep and really investigate your data; if they were to only use aggregated data in the warehouse, they wouldn’t be very useful at all.
So suffice it to say that there are good reasons that product analytics tools haven’t been warehouse-native since day 1. But now that cloud data warehouses are standard, what does the future look like?
Combining the data warehouse and clickstream for maximum profit
This is where Mixpanel’s new launch comes in, and why it’s so interesting. What if you could combine the rigor and breadth of the data in your warehouse with the granularity and depth of clickstream data?
That nice warehouse data helps you tie what your users are doing to business impact, avoid messy data issues with clickstream events, and, in general, get to answers faster. You can bring in data that doesn’t work like a stream, e.g. revenue from Salesforce, stages in a CRM, or ad spend from AdWords. Mixpanel’s Warehouse Connectors does just that.
This might seem simple on the surface, but it actually required some fancy engineering footwork. Since data in the warehouse is constantly changing—the antithetical to immutable clickstream events–Mixpanel developed a technology called Mirror that automatically captures any changes to data that happen in the warehouse. It’s pretty neat.
Here’s an example of a graph that you can only build when you combine clickstream data (users viewing videos) with data warehouse data (tickets from a support desk like Intercom):
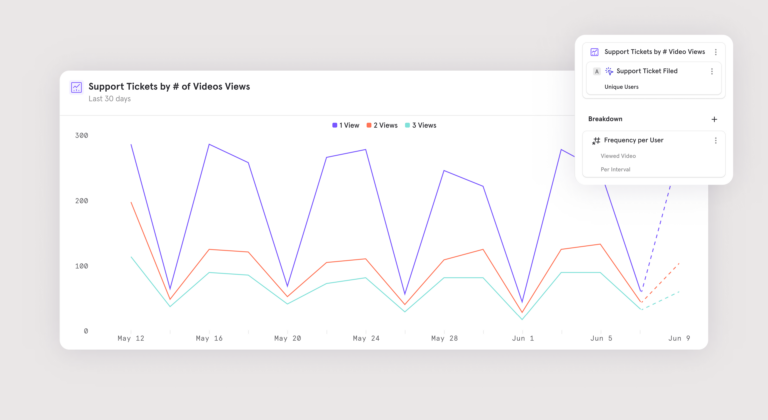
The lucky data team behind this chart can enthusiastically recommend that creating more helpful videos will help reduce the load on the support team.
Where this is all going
Here’s a disclaimer that I’m not privy to Mixpanel’s product roadmap or product positioning. The following are just my thoughts on the exciting future of this analytics space.
Veteran data users among us will astutely note that as product analytics tools like Mixpanel start to integrate data from the warehouse, the once clear lines between product analytics and BI begin to blur. Snowflake has been pushing hard on the warehouse as a platform idea: that it’s not just a place to store data but instead a sort of “operating system” for all of your data workloads. And to boot, the two major BI tools that I grew up with–Tableau and Looker–have both been acquired by larger companies.
So what is product analytics, what is BI, and what is the warehouse? Is everything going to consolidate into a few tools? Will product analytics tools like Mixpanel become the place for companies to do all of their reporting and investigation? We’ll just have to wait and see.